|
Masculine Defaults via Gendered Discourse in Podcasts and Large Language Models
Maria Teleki, Xiangjue Dong, Haoran Liu, and James Caverlee
ICWSM 2025 Presented at IC2S2 (Oral), SICon@ACL
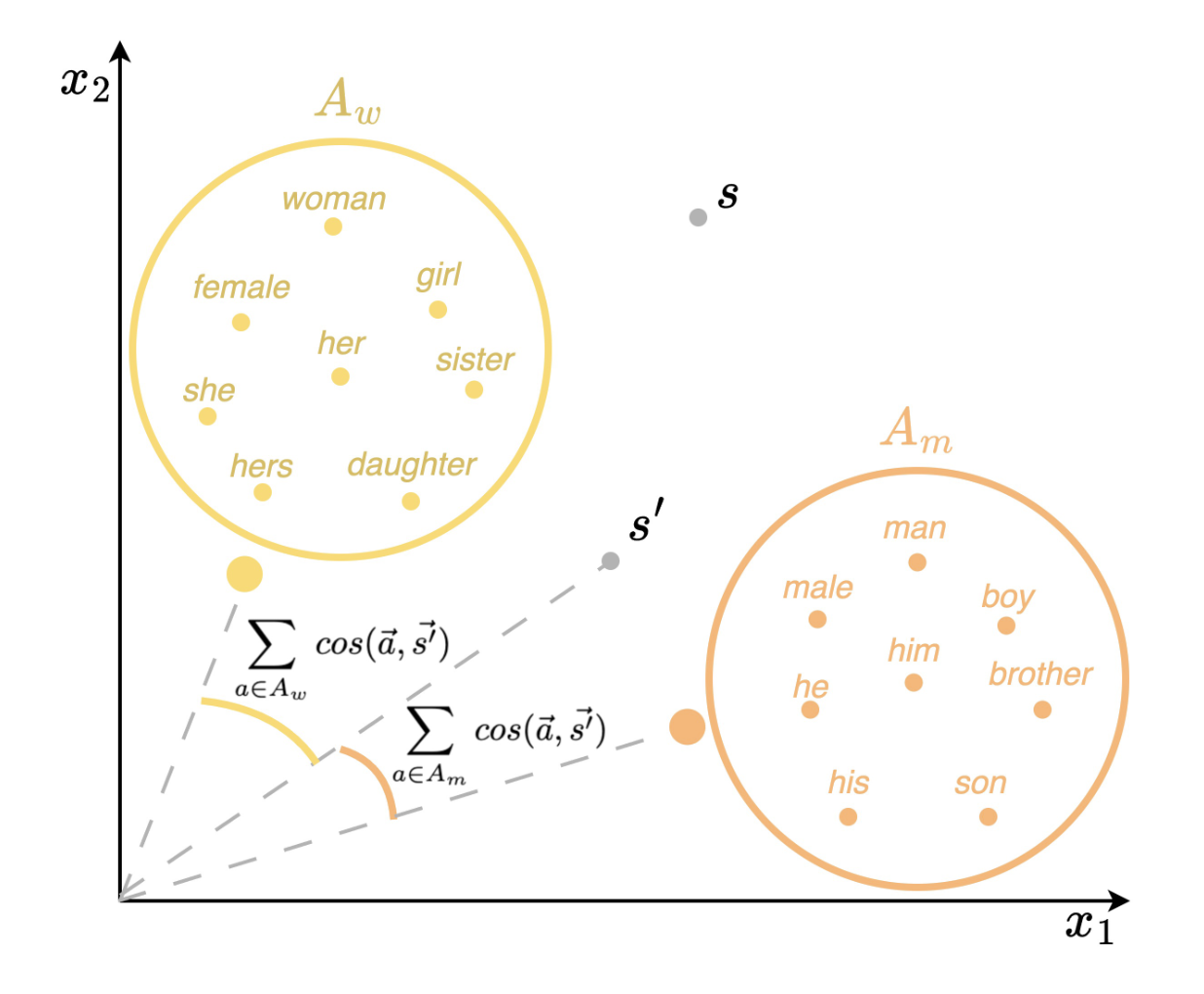
Masculine defaults are widely recognized as a significant type of gender bias, but they are often unseen as they are under-researched. Masculine defaults involve three key parts: (i) the cultural context, (ii) the masculine characteristics or behaviors, and (iii) the reward for, or simply acceptance of, those masculine characteristics or behaviors. In this work, we study discourse-based masculine defaults, and propose a twofold framework for (i) the large-scale discovery and analysis of gendered discourse words in spoken content via our Gendered Discourse Correlation Framework (GDCF); and (ii) the measurement of the gender bias associated with these gendered discourse words in LLMs via our Discourse Word-Embedding Association Test (D-WEAT). We focus our study on podcasts, a popular and growing form of social media, analyzing 15,117 podcast episodes. We analyze correlations between gender and discourse words -- discovered via LDA and BERTopic -- to automatically form gendered discourse word lists. We then study the prevalence of these gendered discourse words in domain-specific contexts, and find that gendered discourse-based masculine defaults exist in the domains of business, technology/politics, and video games. Next, we study the representation of these gendered discourse words from a state-of-the-art LLM embedding model from OpenAI, and find that the masculine discourse words have a more stable and robust representation than the feminine discourse words, which may result in better system performance on downstream tasks for men. Hence, men are rewarded for their discourse patterns with better system performance by one of the state-of-the-art language models -- and this embedding disparity is a representational harm and a masculine default.
@inproceedings{teleki25_icwsm,
title = {Masculine Defaults via Gendered Discourse in Podcasts and Large Language Models},
author = {Maria Teleki and Xiangjue Dong and Haoran Liu and James Caverlee},
year = {2025},
booktitle = {ICWSM 2025}
}
|

|
POSTER"Walk a Mile in My Voice": Voice Conversion Shapes Trust, Attribution, and Empathy in Human–AI Speech Interactions
Shree Harsha Bokkahalli Satish, Maria Teleki, Christoph Minixhofer, Ondrej Klejch, Peter Bell, Éva Székely
Collaboration w/ KTH Royal Institute of Technology, University of Edinburgh
IUI 2026 Presented at CHI
Speech Large Language Models (SpeechLLMs) represent a new generation of conversational AI that processes spoken language directly from audio. This enables sensitivity to prosodic cues while also inheriting voice-based demographic information that has been shown to lead to biased system behaviour. Studying how people react and reflect on AI responses to different gender and accent presentation can contribute to understanding the potential societal impact. In this study, we examine how vocal identity factors of accent and perceived gender shape user evaluations of AI responses while the underlying linguistic content remains constant. Through two complementary studies (Interactive Study, N=24; Observational Study, N=19), we investigate whether experiencing interactions through voice converted identities versus observing pre-recorded conversations affects perceived harm, acceptability, trust, and responsibility attribution. We find that participants who experienced voice conversion rated benign AI responses as significantly more acceptable and reported significantly higher trust compared to those observing identical interactions, while perceived harm remained low across conditions. Qualitative feedback reveals that participants attributed different AI behaviours to voice characteristics, noting perceived differences in tone, helpfulness, and respect based on accent and gender presentation. Our findings suggest that vocal identity functions as a design variable, with systematic effects on user perception even when lexical content is held constant.
title = {\textbf{Walk a Mile in My Voice: Voice Conversion Shapes Trust, Attribution, and Empathy in Human–AI Speech Interactions}},
author = {Shree Harsha Bokkahalli Satish and \underline{Maria Teleki} and Christoph Minixhofer and Ondrej Klejch and Peter Bell and Éva Székely},
year = {2026},
booktitle = {IUI (Short)}
}
|
|
New! Extended VersionA Survey on LLMs for Story Generation
Maria Teleki, Xiangjue Dong, Peter Carragher, Vedangi Bengali, Tian Liu, Haoran Liu, Sai Tejas Janjur, Thomas Docog, Stephanie Birkelbach, Oliver Grabner, Cong Wang, Ting Liu, Yin Zhang, Frank Shipman, James Caverlee
Collaboration w/ Carnegie Mellon University
EMNLP Findings 2025
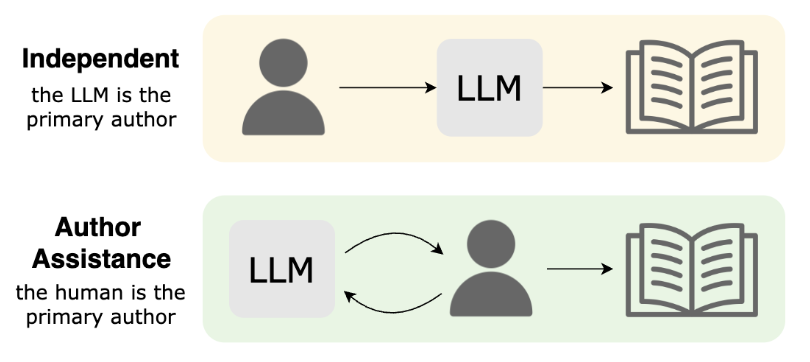
Methods for story generation with Large Language Models (LLMs) have come into the spotlight recently. We create a novel taxonomy of LLMs for story generation consisting of two major paradigms: (i) independent story generation by an LLM, and (ii) author-assistance for story generation -- a collaborative approach with LLMs supporting human authors. We compare existing works based on their methodology, datasets, generated story types, evaluation methods, and LLM usage. With a comprehensive survey, we identify potential directions for future work.
@inproceedings{teleki25_survey,
title = {{A Survey on LLMs for Story Generation}},
author = {Maria Teleki and Vedangi Bengali and Xiangjue Dong and Sai Tejas Janjur and Haoran Liu and Tian Liu and Cong Wang and Ting Liu and Yin Zhang and Frank Shipman and James Caverlee},
year = {2025},
booktitle = {EMNLP Findings}
}
|
|
The Voice Behind the Words: Quantifying Intersectional Bias in SpeechLLMs
Shree Harsha Bokkahalli Satish, Christoph Minixhofer, Maria Teleki, James Caverlee, Ondřej Klejch, Peter Bell, Gustav Eje Henter, Éva Székely
Collaboration w/ KTH Royal Institute of Technology, University of Edinburgh
INTERSPEECH 2026
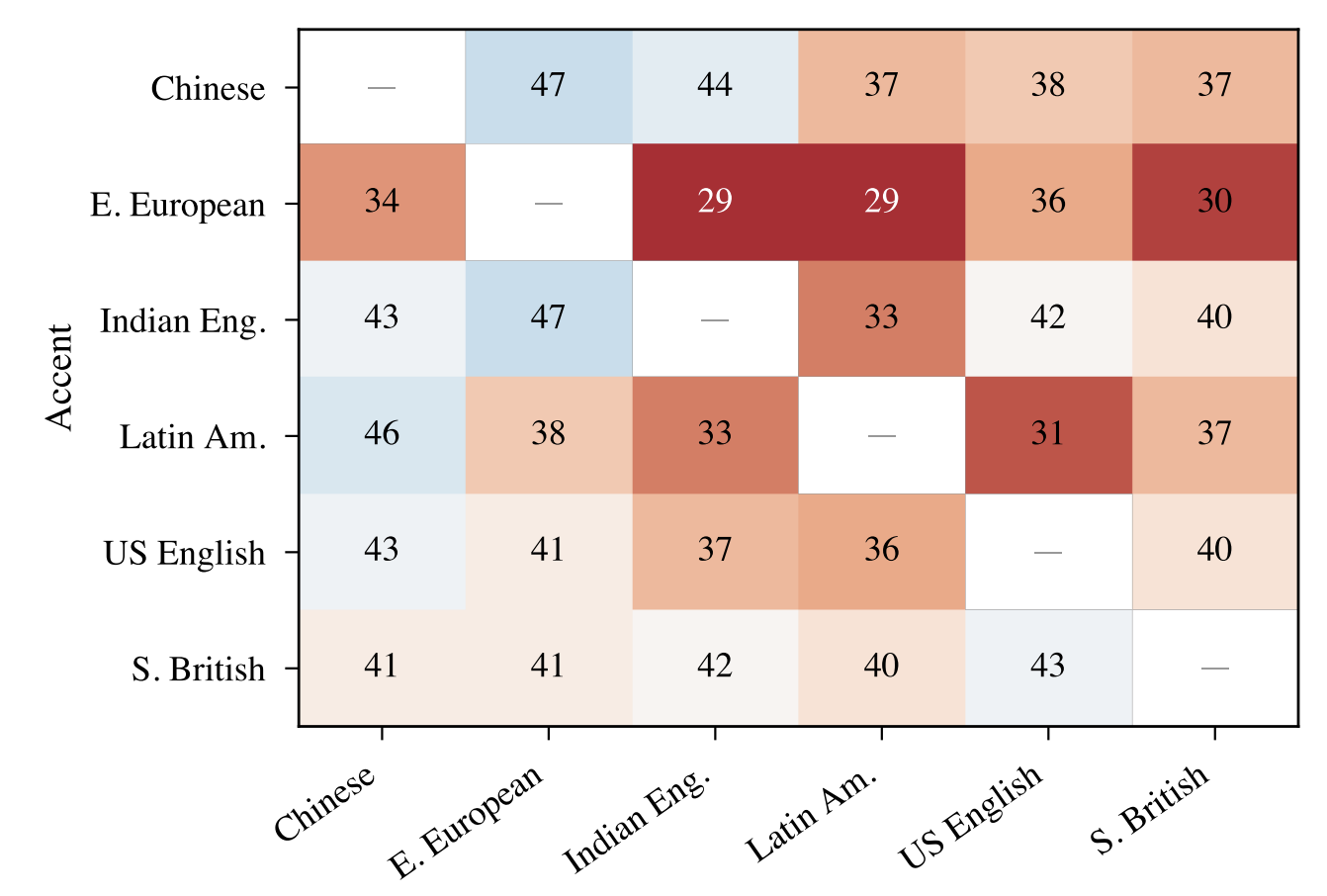
Speech Large Language Models (SpeechLLMs) process spoken input directly, retaining cues such as accent and perceived gender that were previously removed in cascaded pipelines. This introduces speaker identity dependent variation in responses. We present a large-scale intersectional evaluation of accent and gender bias in three SpeechLLMs using 2,880 controlled interactions across six English accents and two gender presentations, keeping linguistic content constant through voice cloning. Using pointwise LLM-judge ratings, pairwise comparisons, and Best-Worst Scaling with human validation, we detect consistent disparities. Eastern European-accented speech receives lower helpfulness scores, particularly for female-presenting voices. The bias is implicit: responses remain polite but differ in helpfulness. While LLM judges capture the directional trend of these biases, human evaluators exhibit significantly higher sensitivity, uncovering sharper intersectional disparities.
@inproceedings{satish26_voicebehind,
title = {The Voice Behind the Words: Quantifying Intersectional Bias in SpeechLLMs},
author = {Shree Harsha Bokkahalli Satish and Christoph Minixhofer and Maria Teleki and James Caverlee and Ondřej Klejch and Peter Bell and Gustav Eje Henter and Éva Székely},
year = {2026},
booktitle = {Interspeech}
}
|
|
CHOIR: Harmonizing Structured Prompt Diversity for Robust LLM Reasoning
Xiangjue Dong, Cong Wang, Maria Teleki, Millennium Bismay, Ruihong Huang, and James Caverlee
ACL 2026
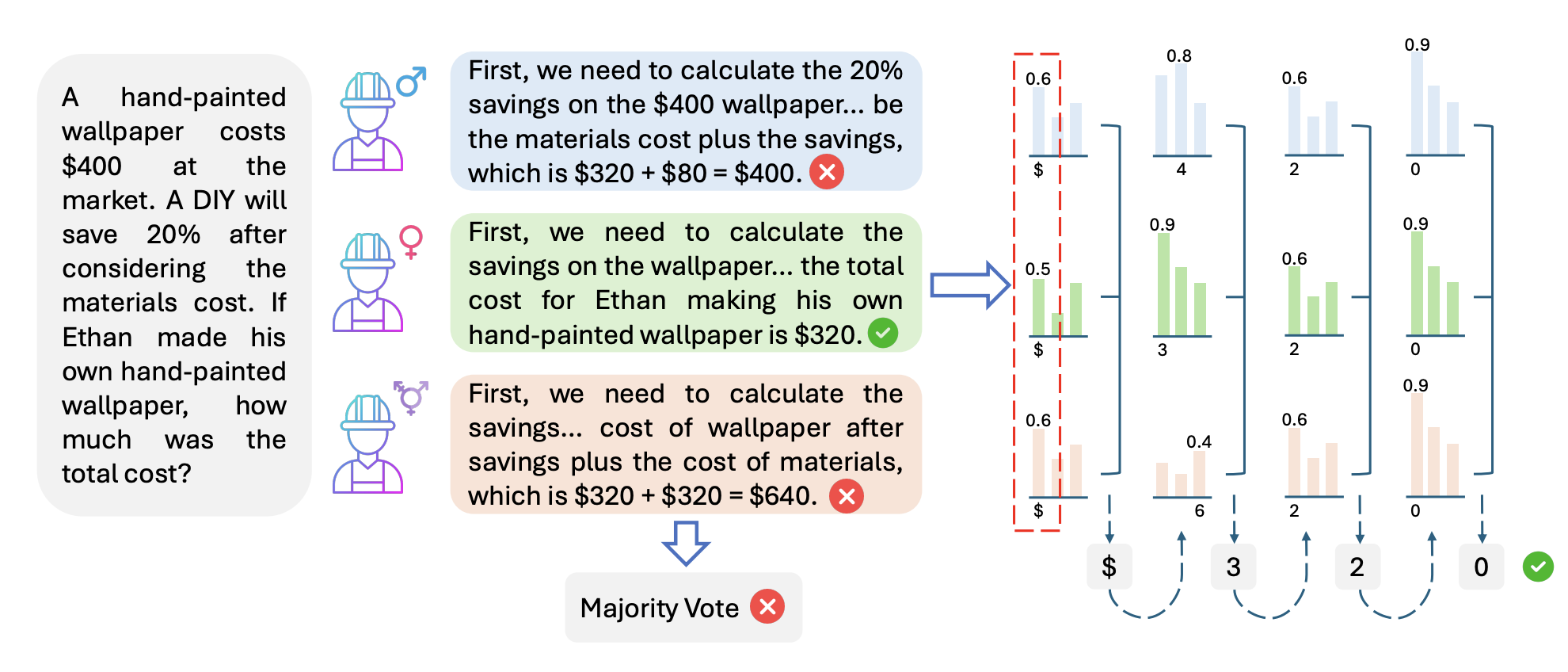
Persona-assigned Large Language Models can adopt diverse roles, enabling personalized and context-aware reasoning. However, even minor demographic perturbations in personas -- such as simple pronoun swaps -- can alter reasoning trajectories, leading to divergent sets of correct answers on reasoning benchmarks. We explore the potential of these variations as a constructive resource to improve LLM reasoning performance. We propose CHOIR (Collaborative Harmonization fOr Inference Robustness), a test-time framework that harmonizes a set of demographically perturbed, persona-conditioned reasoning signals into a unified prediction. CHOIR orchestrates a collaborative decoding process among counterfactual personas -- perturbed in terms of gender, race, religion, disability, and age -- dynamically balancing agreement and divergence in their reasoning paths to improve performance. Experiments demonstrate that CHOIR consistently enhances LLM reasoning across model architectures, scales, and tasks. Improvements reach up to 20.1% for individual groups and 15.1% on average, and we show that CHOIR remains effective even when base personas are suboptimal.
@inproceedings{dong26_choir,
title = {CHOIR: Harmonizing Structured Prompt Diversity for Robust LLM Reasoning},
author = {Xiangjue Dong and Cong Wang and Maria Teleki and Millennium Bismay and Ruihong Huang and James Caverlee},
year = {2026},
booktitle = {ACL 2026}
}
|
|
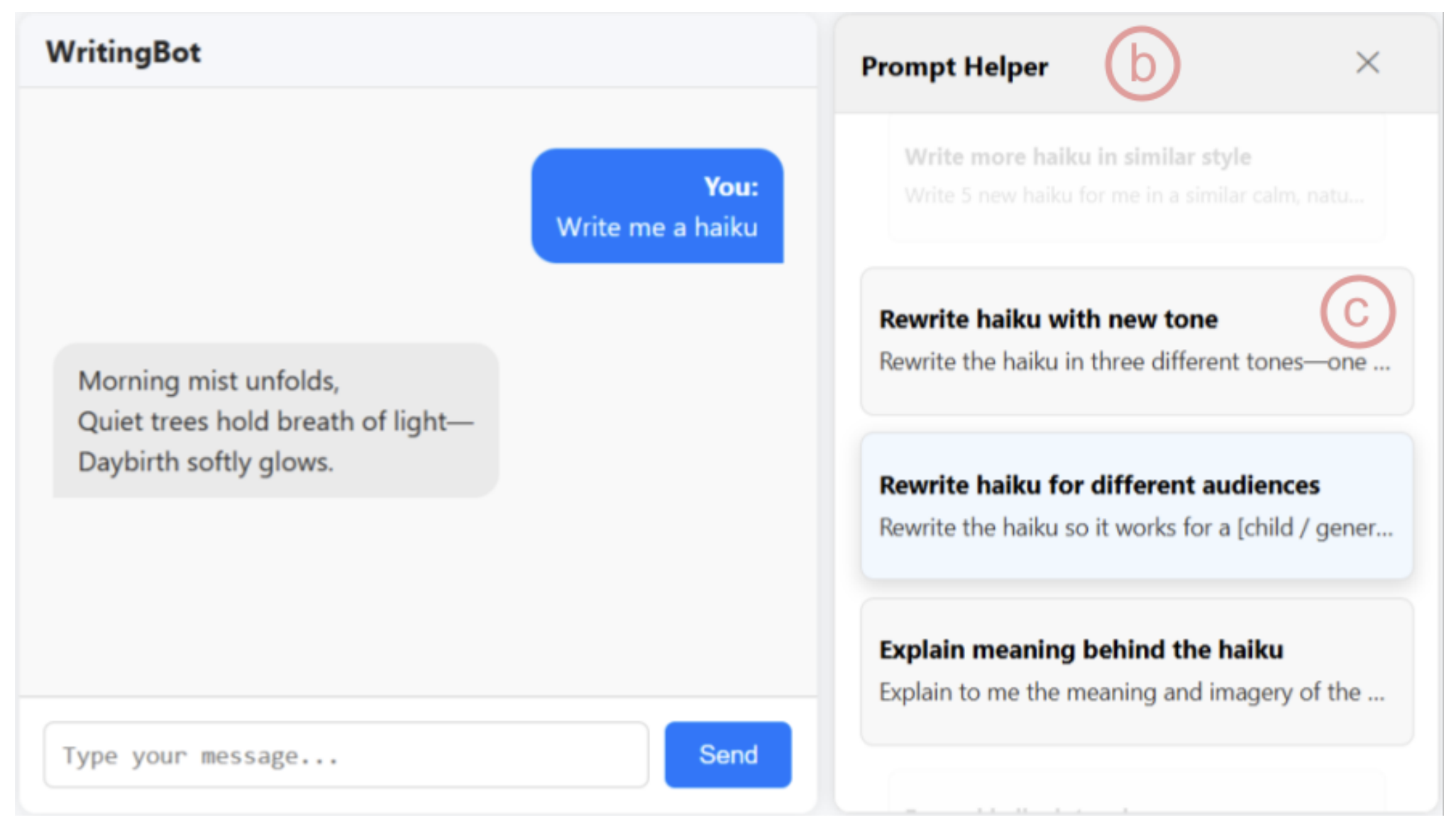
POSTERUG 1ST AUTHORPromptHelper: A Prompt Recommender System for Encouraging Creativity in AI Chatbot Interactions
Jason Kim, Maria Teleki, James Caverlee
CHI 2026
Prompting is central to interaction with AI systems, yet many users struggle to explore alternative directions, articulate creative intent, or understand how variations in prompts shape model outputs. We introduce prompt recommender systems (PRS) as an interaction approach that supports exploration, suggesting contextually relevant follow-up prompts. We present PromptHelper, a PRS prototype integrated into an AI chatbot that surfaces semantically diverse prompt suggestions while users work on real writing tasks. We evaluate PromptHelper in a 2x2 fully within-subjects study (N=32) across creative and academic writing tasks. Results show that PromptHelper significantly increases users' perceived exploration and expressiveness without increasing cognitive workload. Qualitative findings illustrate how prompt recommendations help users branch into new directions, overcome uncertainty about what to ask next, and better articulate their intent. We discuss implications for designing AI interfaces that scaffold exploratory interaction while preserving user agency, and release open-source resources to support research on prompt recommendation.
@inproceedings{kim26_prompthelper,
title = {{PromptHelper: A Prompt Recommender System for Encouraging Creativity in AI Chatbot Interactions}},
author = {Jason Kim and Maria Teleki and James Caverlee},
year = {2026},
booktitle = {arXiv}
}
|
|
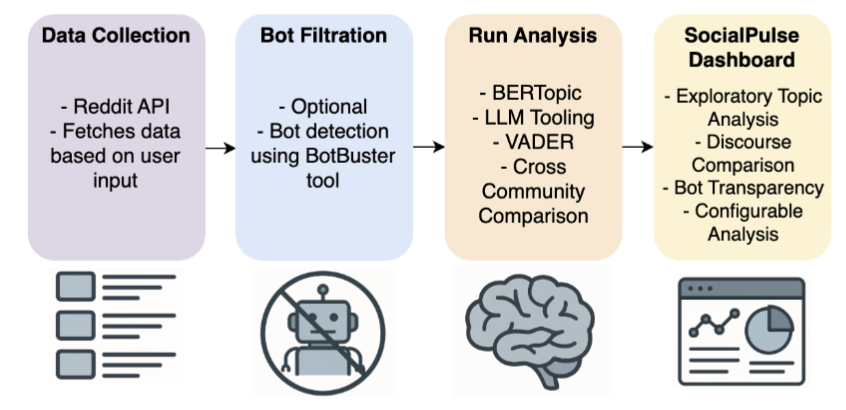
SHORTUG 1ST AUTHORSocialPulse: An Open-Source Subreddit Sensemaking Toolkit
Stephanie Birkelbach, Maria Teleki, Peter Carragher, Xiangjue Dong, Nehul Bhatnagar, James Caverlee
Collaboration w/ Carnegie Mellon University, Revionics
SocialLLM@ICWSM 26 Presented at IC2S2 (Oral)
Understanding how online communities discuss and make sense of complex social issues is a central challenge in social media research, yet existing tools for large-scale discourse analysis are often closed-source, difficult to adapt, or limited to single analytical views. We present SocialPulse, an open-source subreddit sensemaking toolkit that unifies multiple complementary analyses -- topic modeling, sentiment analysis, user activity characterization, and bot detection -- within a single interactive system. SocialPulse enables users to fluidly move between aggregate trends and fine-grained content, compare highly active and long-tail contributors, and examine temporal shifts in discourse across subreddits. The demo showcases end-to-end exploratory workflows that allow researchers and practitioners to rapidly surface themes, participation patterns, and emerging dynamics in large Reddit datasets. By offering an extensible and openly available platform, SocialPulse provides a practical and reusable foundation for transparent, reproducible sensemaking of online community discourse.
@inproceedings{birkelbach26_socialpulse,
title = {{SocialPulse: An Open-Source Subreddit Sensemaking Toolkit}},
author = {Stephanie Birkelbach and Maria Teleki and Peter Carragher and Xiangjue Dong and Nehul Bhatnagar and James Caverlee
year = {2026},
booktitle = {arXiv}
}
|
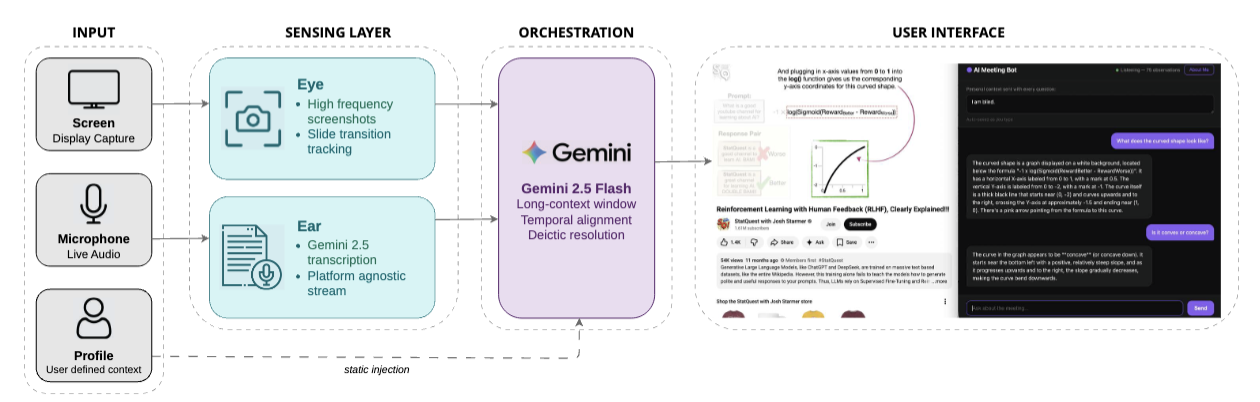 |
DEMOAI in the Loop: A Multimodal Assistant for Real-Time Lecture Comprehension
Amanda Lacy, Maria Teleki, Esau Hutcherson, Jobin Varughese, Jun Kwon, Frank Shipman, Tracy Hammond
L@S 2026
Synchronous learning environments often present a bandwidth problem where high-density visual and auditory information is lost due to fast-paced delivery or inaccessible presentation methods. We present AI in the Loop, a multimodal assistant that supports real-time lecture comprehension by integrating live speech recognition, slide content extraction, and an LLM-powered question answering interface. The system allows students to query lecture content in natural language during class, receiving contextually grounded responses drawn from both spoken audio and displayed slides. Our demo showcases the system in a live classroom setting, highlighting its potential to reduce cognitive load and support diverse learners.
@inproceedings{lacy-etal-2026-aiintheloop,
title = "{AI} in the Loop: A Multimodal Assistant for Real-Time Lecture Comprehension",
author = "Lacy, Amanda and
Teleki, Maria and
Hutcherson, Esau and
Varughese, Jobin and
Kwon, Jun and
Shipman, Frank and
Hammond, Tracy",
booktitle = "Proceedings of the Thirteenth ACM Conference on Learning at Scale",
year = "2026",
}
|
|
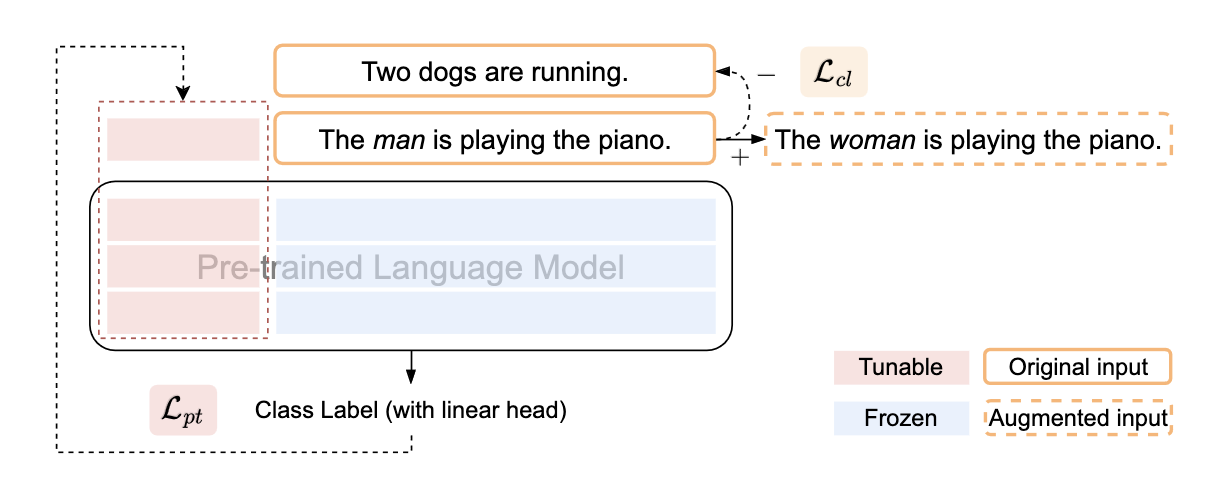
Co2PT: Mitigating Bias in Pre-trained Language Models through Counterfactual Contrastive Prompt Tuning
Xiangjue Dong, Ziwei Zhu, Zhuoer Wang, Maria Teleki, and James Caverlee
Collaboration w/ George Mason University
EMNLP Findings 2023
Pre-trained Language Models are widely used in many important real-world applications. However, recent studies show that these models can encode social biases from large pre-training corpora and even amplify biases in downstream applications. To address this challenge, we propose Co2PT, an efficient and effective debias-while-prompt tuning method for mitigating biases via counterfactual contrastive prompt tuning on downstream tasks. Our experiments conducted on three extrinsic bias benchmarks demonstrate the effectiveness of Co2PT on bias mitigation during the prompt tuning process and its adaptability to existing upstream debiased language models. These findings indicate the strength of Co2PT and provide promising avenues for further enhancement in bias mitigation on downstream tasks.
@inproceedings{dong-etal-2023-co2pt,
title = "{C}o$^2${PT}: Mitigating Bias in Pre-trained Language Models through Counterfactual Contrastive Prompt Tuning",
author = "Dong, Xiangjue and
Zhu, Ziwei and
Wang, Zhuoer and
Teleki, Maria and
Caverlee, James",
editor = "Bouamor, Houda and
Pino, Juan and
Bali, Kalika",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2023",
month = dec,
year = "2023",
address = "Singapore",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-emnlp.390",
doi = "10.18653/v1/2023.findings-emnlp.390",
pages = "5859--5871",
abstract = "Pre-trained Language Models are widely used in many important real-world applications. However, recent studies show that these models can encode social biases from large pre-training corpora and even amplify biases in downstream applications. To address this challenge, we propose Co$^2$PT, an efficient and effective *debias-while-prompt tuning* method for mitigating biases via counterfactual contrastive prompt tuning on downstream tasks. Our experiments conducted on three extrinsic bias benchmarks demonstrate the effectiveness of Co$^2$PT on bias mitigation during the prompt tuning process and its adaptability to existing upstream debiased language models. These findings indicate the strength of Co$^2$PT and provide promising avenues for further enhancement in bias mitigation on downstream tasks.",
}
|




![[Smiling]](img/apollo-smile.png){kind=link}
![[Sunflowers]](img/apollo-david-sunflower.jpeg){kind=link}
![[Generated-1]](img/apollo-generated1.png){kind=link}
![[On top of volcano in Hawaii]](img/hawaii-volcano.jpeg){kind=link}
![[Casper, Wyoming]](img/wyoming.jpeg){kind=link}
![[Bastrop, Texas]](img/apollo-pinetrees.png){kind=link}